

Bu yazıda sıkıştırılmış (encode) ve “gizli” (latent) vektörü elde edilmiş bir görüntünün farklı modeller ve yöntemler kullanılarak geri oluşturulmasını (decode) ve bu modellerin sonuçları arasındaki başarı farklılıklarını ele alacağız.
Sıkıştırma (Encode)
Bir görüntüyü encode etmek veya “gizli” (latent) vektör elde etmek, genellikle makine öğrenimi ve derin öğrenme modellerinde kullanılan bir tekniktir. Bu işlem, bir girdi verisini daha düşük boyutlu, anlamlı bir temsil haline getirme sürecidir. Veri saklama, boyut azaltma, özellik çıkarımı (feature extraction), transfer öğrenme (transfer learning) vb. alanlarda bu latent vektörler kullanılır.
Bu yazıda görüntülerin veritabanında saklanırken daha az yer kaplaması için encode edilmesi amaçlanmaktadır. Ancak bu yazıda depolama süreci ele alınmayıp, sadece görüntü encode-decode süreçleri anlatılacaktır.
Encode işleminin gerçekleşmesi için “Stable Diffusion” olarak adlandırılan , görüntü üretme teknolojisinde kullanılan Değişken Otomatik Kodlayıcı (Variational Auto Encoder, VAE) modeli kullanılacaktır. VAE kullanılarak encode edilen görüntüden elde edilen düşük boyutlu latent vektörlerin daha sonra çözümlenerek kullanılması sağlanacaktır.
VAE kullanılarak 3 kanallı, boyutları M,N olan bir resim (M,N,3), 4 kanallı ve 8 kat küçük boyutta (M/8,N/8,4) bir latent vektöre dönüştürülür. Bu sayede 48 kat sıkıştırma sağlanmaktadır. Sonrasında sıkıştırılan veri istenilen veri tabanına kaydedilebilir. Bu sürecin şeması Şekil 1’de gösterilmektedir.
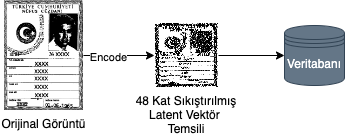
Aşağıdaki kod parçacığında da latent vektörün nasıl elde edildiği gösterilmektedir. Bu yazıda “diffusers” kütüphanesi ile görüntünün sıkıştırılması sağlanmıştır. Bu örnekte (1, 256, 256, 3) boyutlarında olan görüntüden sıkıştırma sonucu elde ettiğimiz “latent” değişkeni [1, 4, 64, 64] boyutlarında bir vektördür, yani boyutu girdi görüntüsünün 8’er kat küçük halidir.
import torch
from diffusers import StableDiffusionPipeline
from consistencydecoder import ConsistencyDecoder, save_image, load_image
# encode with stable diffusion vae
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, device="cuda:0"
)
pipe.vae.cuda()
decoder_consistency = ConsistencyDecoder(device="cuda:0") # Model size: 2.49 GB
image = load_image("image.png", size=(512, 512), center_crop=True)
latent = pipe.vae.encode(image.half().cuda()).latent_dist.meanGeri Oluşturma (Decode)
Görüntü, encode sonucu elde ettiğimiz ve veritabanında sakladığımız bir latent vektörün decode işleminden geçirilmesiyle eski haline getirilir. Ancak bu encode ve decode işlemi kayıplı çalışmaktadır. Yani, orijinal görüntü birebir geri getirilemez. Bu yazının devamında iki farklı decode modelinin geri oluşturma başarısını inceliyor olacağız.
Görüntüyü sıkıştırmak için kullandığımız Stable Diffusion modeli ve “OpenAI” şirketi tarafından daha güncel zamanda geliştirilmiş olan “consistency decoder” modellerini kullanarak sıkıştırılmış görüntüleri geri oluşturacağız. Böylece iki modelin decode işlemindeki başarılarını kıyaslayacağız.
Öncelikle decode süreci Şekil 2’deki şemada gösterildiği gibi ilerlemektedir. Görüntünün latent vektörü çekilir ve decode işleminden geçip eski hali elde edilir.
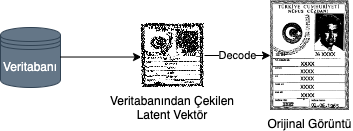
Aşağıdaki kod parçacığında decode işleminin, sıkıştırma yaparken kullanılan modelle nasıl sağlandığı gösterilmiştir. Encode sonucu elde edilen “latent” değişkeni bu model sayesinde decode edilir ve oluşan yeni görüntü kaydedilir.
sample_stable_diffusion = pipe.vae.decode(latent).sample.detach()
save_image(sample_stable_diffusion, "stable_diff_decode_result.png")Aşağıdaki kod parçacığında ise decode işlemi “consistency decoder” modeli kullanılarak sağlanmıştır. Yine aynı “latent” değişkeni bu model ile decode edilir ve oluşan yeni görüntü kaydedilir.
sample_consistency = decoder_consistency(latent)
save_image(sample_consistency, "consistency_decode_result.png")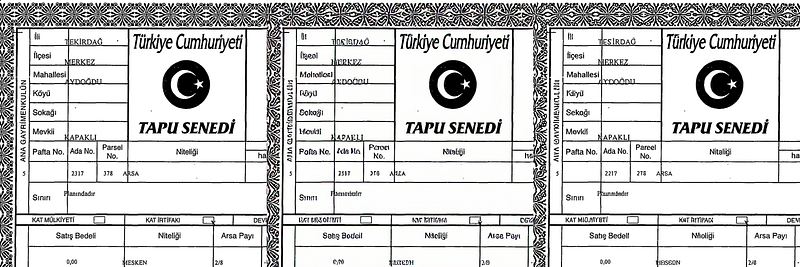
Şekil 3’te sıkıştırılan örnek bir görüntünün orijinal halini, sıkıştırılan modelle yapılan decode sonucunu ve consistency decoder ile elde edilen decode sonucu gösterilmektedir.
Sonuç
Daha önce de belirtildiği üzere görüntüler encode-decode işleminden geçtiğinde görüntülerde bozulmalar meydana gelmekte. Bu bozulmaların minimuma indirilmesi için güncel modeller ve yöntemler geliştirilmekte. Bu yazıda bu sorun için güncel olarak geliştirilmiş olan “consistency decoder” modelini kullanarak bir karşılaştırma sağlanmıştır.
Her iki decode sonucunda da görüntülerde bozulma olduğu görülmekte. Ancak consistency decoder ile elde edilen sonucun orijinale daha yakın olduğu, yazıların daha okunur olduğu görülmekte. Örnek sayısını farklı bir türle çoğaltmak için aynı süreçleri Şekil 4’teki örnek için de tekrarlanmış ve bu örnekte de geliştirilen bu yeni modelin daha başarılı sonuç verdiği gözlemlenmiştir.

Consistency decoder hakkında daha fazla bilgi edinmek ve uygulama örnekleri görmek için kendi GitHub sayfalarını ve bu modelin incelendiği makaleleri inceleyebilirsiniz. Başarılar dilerim!